How do search engines work?
Search engines work by taking a list of known URLs, which then go to the scheduler. The scheduler decides when to crawl each URL. Crawled pages then go to the parser where vital information is extracted and indexed. Parsed links go to the scheduler, which prioritizes their crawling and re-crawling.
When you search for something, search engines return matching pages, and algorithms rank them by relevance.
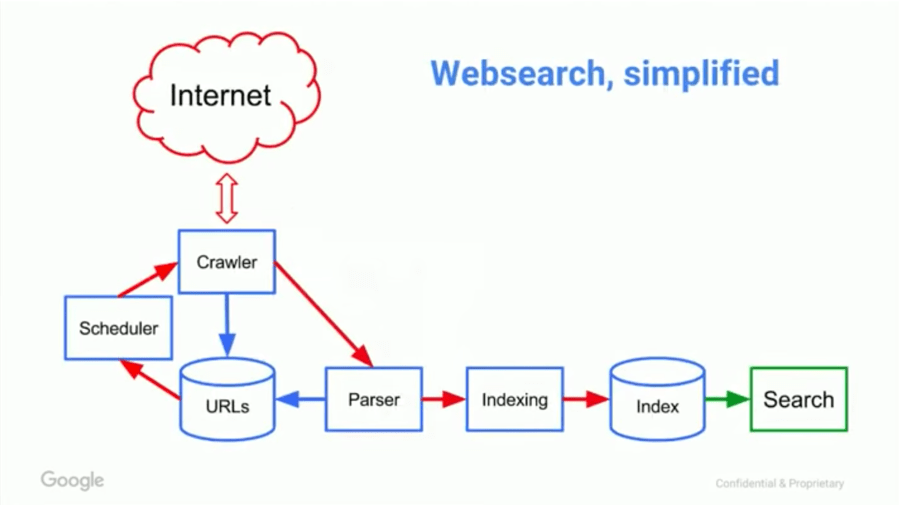
We’ll cover ranking algorithms shortly. First, let’s drill deeper into the mechanisms used to build and maintain a web index to make sure we understand how they work. These are scheduling, crawling, parsing, and indexing.
Scheduling
The scheduler assesses the relative importance of new and known URLs. It then decides when to crawl new URLs and how often to re-crawl known URLs.
Crawling
The crawler is a computer program that downloads web pages. Search engines discover new content by regularly re-crawling known pages where new links often get added over time.
For example, every time we publish a new blog post, it gets pushed to the top of our blog homepage, where there’s a link.

Showing links to our latest blog posts on the Ahrefs Blog homepage.
When a search engine like Google re-crawls that page, it downloads the content of the page with the recently-added links.
The crawler then passes the downloaded web page to the parser.
Parsing
The parser extracts links from the page, along with other key information. It then sends extracted URLs to the scheduler and extracted data for indexing.
Indexing
Indexing is where parsed information from crawled pages gets added to a database called a search index.
Think of this as a digital library of information about trillions of web pages.